In the world of AI training, a "perfect" course is often a contradiction in terms. By the time you have polished the last transition and signed off the final slide, the model you were teaching has been updated — and your masterpiece has quietly become a historical artefact. The production calendar does not care that you spent three months on it.
Adopting agile principles in L&D is not simply about producing content faster. It is about building a communication structure that keeps training connected to operational reality — one that closes the gap between the 88% of organisations using AI and the 5% of employees using it in ways that actually transform their work. We explored why that gap exists and what it costs here. This article is about what to do about it from an L&D design perspective.
The four principles below are not a methodology overhaul. They are practical shifts in how AI training is conceived, produced, distributed, and maintained — shifts that make the difference between a training programme that leads and one that perpetually catches up.
Traditional L&D treats production quality as a proxy for training quality. High-fidelity video, exhaustive scripts, and refined interactions signal that the content was taken seriously. For stable topics, this logic holds. For AI literacy, it breaks down — because the time required to achieve that polish is time during which the content is becoming outdated.
The metric that matters for AI training is not visual quality. It is factual currency. A straightforward module that accurately reflects how a tool behaves today will do more for a learner than a polished module that describes how it behaved six months ago. If someone is struggling with an AI workflow right now, they need accurate guidance now — not a beautifully animated explanation of a feature that no longer works that way.
This does not mean abandoning quality standards. It means separating two things that traditional L&D treats as inseparable: the quality of the content and the production value of its delivery. Fix the content first. Refine the visual experience over time as the module proves its value and earns the investment.
Agile L&D is not just about how content is built. It is about how information flows between the people who train, the people who operate, and the people who catch failures. In most organisations, these groups are further apart than anyone would design them to be if starting from scratch. A QA team identifies an AI error in a customer support ticket. It gets fixed. The ticket is closed. Nobody tells L&D that the error was systemic, that it reflects a gap in how employees were trained to use the tool, or that the same mistake will almost certainly happen again next week.
An agile training function treats operational errors as training inputs. The mistake in operations becomes the lesson in tomorrow's module — not through a slow editorial cycle, but through a direct, structured pipeline between the teams that observe failures and the team responsible for preventing them.
GitLab operates on what they call a handbook-first principle: every process change is documented in a shared, employee-accessible handbook before it is communicated anywhere else. When a team lead identifies an anomaly in an AI-assisted workflow, the fix does not go into an email or a team meeting — it goes into the handbook. The "training" updates the moment the "truth" changes.
The result is a system where QA, Operations, and L&D are always working from the same current version of reality, rather than from a combination of the official training, the unwritten workarounds people have developed, and whatever was discussed in last month's all-hands. The bottleneck between knowing something and teaching it is eliminated.
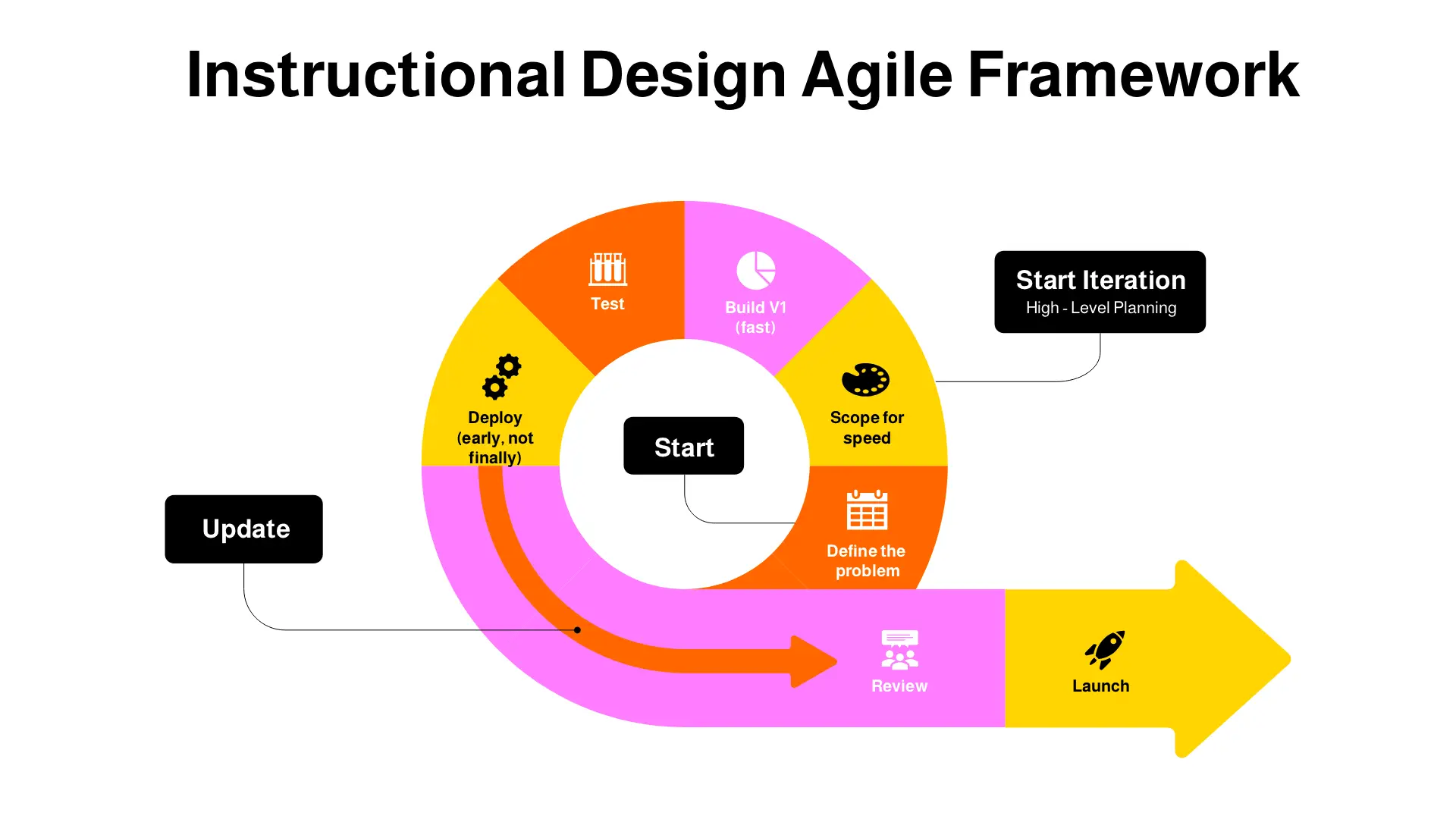
In the traditional six-stage L&D cycle, Deploy & Iterate is the final stage: the step you reach after everything else is complete. In an agile approach to AI training, it is more usefully thought of as the stage the entire cycle is building toward, and one that never actually ends. A course launch is not a conclusion. It is the beginning of a feedback loop.
For AI literacy specifically, this mindset shift has a concrete implication: every course should launch as a version 1.0, with a scheduled review cadence built in from the start. Not a vague intention to "revisit it when something changes," but a named date, a named owner, and a clear trigger for what would prompt an earlier update. When a new model version is released, when a prompt technique stops working as expected, when QA data reveals a pattern of errors — these are update triggers, and the team needs to be ready to act on them in days, not quarters.
A team builds a course on working effectively with a specific AI model. A minor update to the next version changes context window behaviour and introduces new reasoning capabilities that render some of the course's guidance inaccurate. An agile team does not rewrite the course. They push a targeted patch — a short update, a revised section, a prompt library amendment — that reflects the new technical reality. The course keeps working. The learners stay current. The investment in the original build is protected rather than discarded.
Most employees do not need a comprehensive understanding of how large language models work. They need to know how to use AI safely and effectively in the specific context of their job — what to put in, what to question, what to do when the output does not look right. Training that starts from neural architecture or token limits before reaching the practical application has already lost most of its audience.
Effective AI training targets the on-the-job decision, not the theoretical underpinning. What should a customer service agent do when an AI-drafted response contains a claim they cannot verify? What should a data analyst do when a model output looks anomalous? These are answerable in a short, scenario-based module. They do not require a forty-five-minute course on AI fundamentals as a prerequisite.
IBM's approach to employee AI upskilling has leaned heavily on microlearning — short, targeted modules delivered at the point of need rather than through scheduled training programmes. Research into the long-term impact of microlearning on employee retention consistently finds that shorter, more frequent learning interventions produce better knowledge retention than longer, less frequent ones — not because brevity is inherently better, but because information encountered close to the moment it is needed is more likely to stick than information stored for a future situation the learner cannot yet imagine.
For AI training, this maps directly onto how models actually get used. Nobody consults a training course mid-task. But a short guide embedded in a tool interface, a two-minute prompt refresher triggered by a specific workflow step, or a peer-shared note on a failure pattern encountered yesterday — these reach learners at exactly the moment they are ready to use the information.
Khan Academy's AI tutor feature follows the same logic from a different direction: rather than front-loading instruction, it delivers small, contextual prompts and hints at the moment a learner encounters a problem. The learner is not overwhelmed by comprehensiveness. They are given exactly what they need to take the next step. That is the standard worth applying to workplace AI training.
The Real Bottleneck Is Not Capacity
When AI training programmes fall short, the instinct is often to conclude that the L&D team does not have enough bandwidth — that more resource, more time, or a bigger budget would solve the problem. Sometimes that is true. More often, the constraint is not capacity but assumption: the assumption that AI literacy has to be delivered in a particular format, at a particular production standard, through a particular review process.
If your QA team is finding errors that your training is not covering, the problem is unlikely to be the content itself. It is the connection between the people who observe failures and the people responsible for preventing them. An agile training function is a communication structure — one that ensures the distance between a mistake happening in production and a lesson appearing in training is measured in days, not months.
Our AI literacy courses are designed around practical, scenario-based learning that targets real decisions — and updated as the technology evolves, not locked into a production cycle that outlasts the content.
Explore AI Literacy Courses →